When an AI agent makes a high-stakes decision — approving a claim, escalating an incident, authorising a procedure — knowing what it decided isn't enough. You need to know whether the reasoning behind that decision was structurally sound before it commits.
That's what SENTINEL does. It sits behind agentgateway as an MCP server and audits agent reasoning quality in real time — checking whether evidence was complete, current, and properly weighted before a decision goes through.
I built SENTINEL for the AI Agent & MCP Hackathon (Secure & Govern MCP track). It demonstrates how agentgateway's MCP governance primitives — RBAC, session management, audit logging — can be combined with domain-specific reasoning audits to create a practical governance layer for autonomous agents.
The Problem: Confidence ≠ Reliability
Consider a healthcare AI agent — MedAgent — processing prior authorisation decisions. It evaluates whether an insurance payer will approve or deny a requested procedure. On Aetna claims, MedAgent reports 89% confidence. That number looks fine in any dashboard.
But SENTINEL has been tracking actual outcomes for 60 days. The reality:
- 60 days ago, MedAgent's Aetna accuracy was 84% — healthy.
- Around day 30, Aetna quietly updated their prior auth policy for biologics.
- MedAgent's training data and vector DB cache still reference the old policy.
- Today, actual accuracy has drifted to 44%. Worse than a coin flip.
- MedAgent doesn't know. Its confidence is still 89%.
Without SENTINEL, every one of those decisions auto-executes. Patients receive incorrect denials. Appeals pile up. Revenue leaks. Nobody notices until a quarterly audit — weeks or months later.
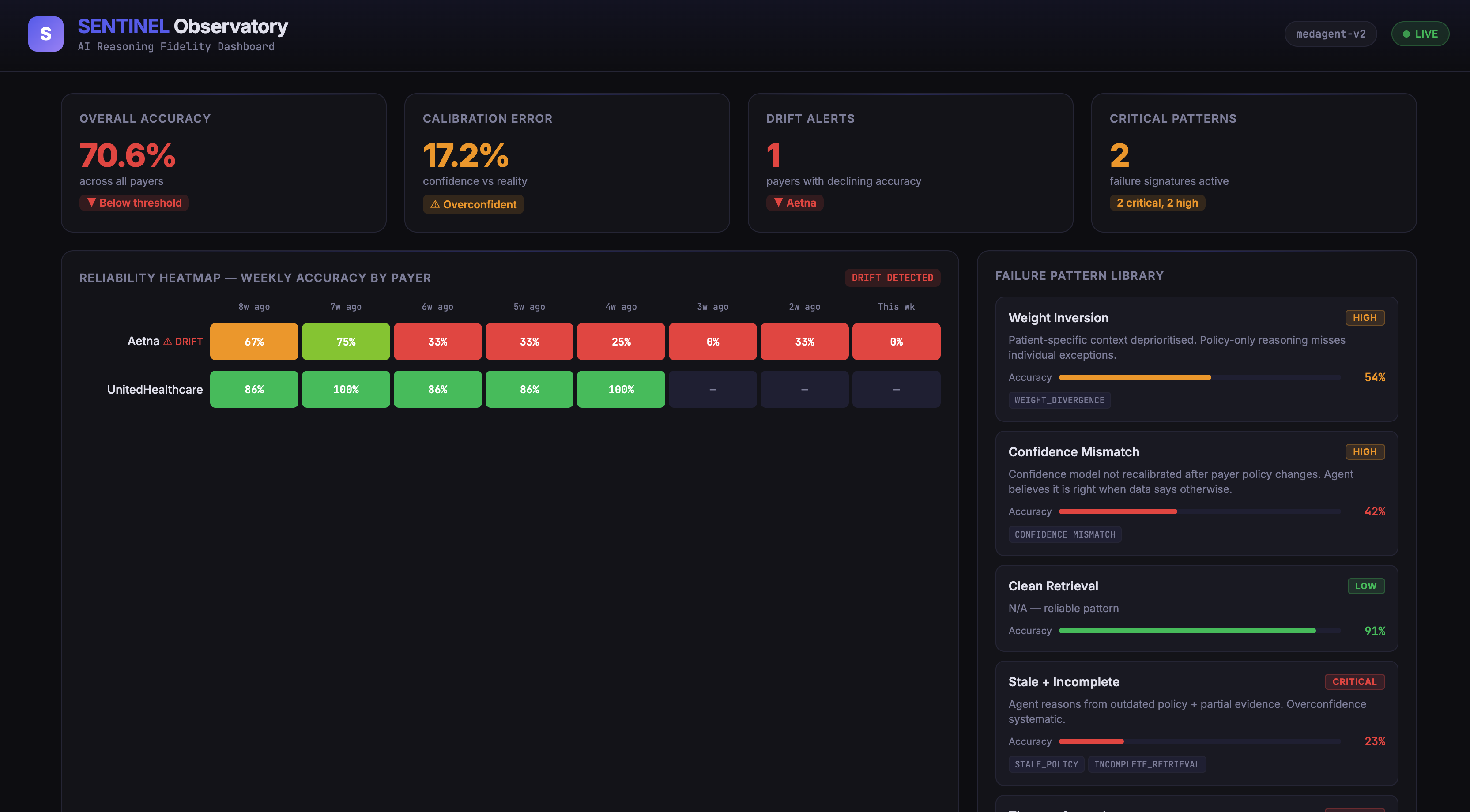
SENTINEL Observatory Dashboard — The reliability heatmap shows Aetna's accuracy declining week over week while UnitedHealthcare remains healthy.
Architecture: MCP Server Behind agentgateway
SENTINEL is built in Go and runs as an MCP server (Streamable HTTP transport) behind Solo.io's agentgateway. The architecture:
MCP Clients (Claude, GPT, Custom Agents)
│
▼
┌─────────────────────────────────┐
│ agentgateway (:3000) │
│ • CEL-based RBAC per MCP tool │
│ • Session management │
│ • Audit logging (all calls) │
│ • CORS for playground access │
└────────────┬────────────────────┘
│ Streamable HTTP
▼
┌─────────────────────────────────┐
│ SENTINEL MCP Server (:8081) │
│ 4 MCP Tools │
└────────────┬────────────────────┘
│
┌────────┼────────┬───────────┐
▼ ▼ ▼ ▼
Fidelity Pattern Reliability Authority
Auditor Library Scorer Gate
agentgateway adds the security and governance layer that SENTINEL itself doesn't need to implement. CEL policies control who can call which tool:
mcpAuthorization:
rules:
# Public — anyone can read failure patterns
- 'mcp.tool.name == "sentinel_patterns"'
- 'mcp.tool.name == "sentinel_reliability"'
# Authenticated — JWT required to run evaluations
- 'mcp.tool.name == "sentinel_evaluate" && has(jwt.sub)'
# Privileged — operator role to pull from Datadog
- 'mcp.tool.name == "sentinel_pull_decisions" && has(jwt.sub) && "operator" in jwt.roles'
This means read-only tools (patterns, reliability) are accessible to any MCP client. Running the evaluation pipeline requires authentication. Pulling raw decision events from Datadog requires operator privileges. All invocations are audit-logged through agentgateway.
agentgateway UI — SENTINEL's MCP tools visible in the gateway with tool-level RBAC enforcement via CEL policies.
The Four-Stage Pipeline
When an agent decision arrives at sentinel_evaluate, it passes through four stages:
Stage 1 — Signal Fidelity Audit
SENTINEL inspects every piece of evidence the agent retrieved. For each signal (payer policy, patient history, step therapy docs, clinical criteria), it checks:
- Staleness: Is the payer policy older than 30 days? →
STALE_POLICYflag (CRITICAL) - Completeness: Did retrieval return all requested pages? →
INCOMPLETE_RETRIEVALflag - Timeouts: Did any critical signal retrieval time out? →
TIMEOUT_ON_CRITICALflag - Weight divergence: Did the agent over/under-weight a signal vs baseline? →
WEIGHT_DIVERGENCEflag - Missing signals: Were required signals never retrieved at all? →
MISSING_SIGNALflag - Confidence calibration: Does stated confidence exceed historical accuracy by >20 points? →
CONFIDENCE_MISMATCHflag
The output is a fidelity score (0.0–1.0) with per-signal audit details and suggested fixes.
Stage 2 — Pattern Classification
The fidelity flags are matched against a library of learned failure signatures. Each pattern carries historical accuracy data:
- Pattern Alpha — Clean retrieval. Historical accuracy: 91%. No concerns.
- Pattern Delta — Stale policy + incomplete retrieval. Historical accuracy: 23%. The "silent killer" pattern.
- Pattern Echo — Timeout cascade. Historical accuracy: 31%. Vector DB cache staleness causing timeouts.
- Pattern Ghost — Weight inversion. Historical accuracy: 54%. Patient history deprioritised.
- Pattern Sigma — Confidence mismatch. Historical accuracy: 42%. Uncalibrated confidence model.
Pattern accuracy updates via exponential moving average as new outcomes resolve.
SENTINEL Pattern Library — Each failure signature carries historical accuracy data. Pattern Delta (Stale + Incomplete) has only 23% accuracy.
Stage 3 — Reliability Scoring
SENTINEL maintains rolling accuracy profiles per agent × payer combination. It computes:
- Overall accuracy across all payers
- Per-payer breakdown with weekly accuracy timeseries (last 8 weeks)
- ECE (Expected Calibration Error) — how well confidence tracks reality
- Drift detection — comparing latest week vs 4-week average, triggering when accuracy drops >20%
- Confidence-reality gap — bucketed analysis showing where the agent overestimates
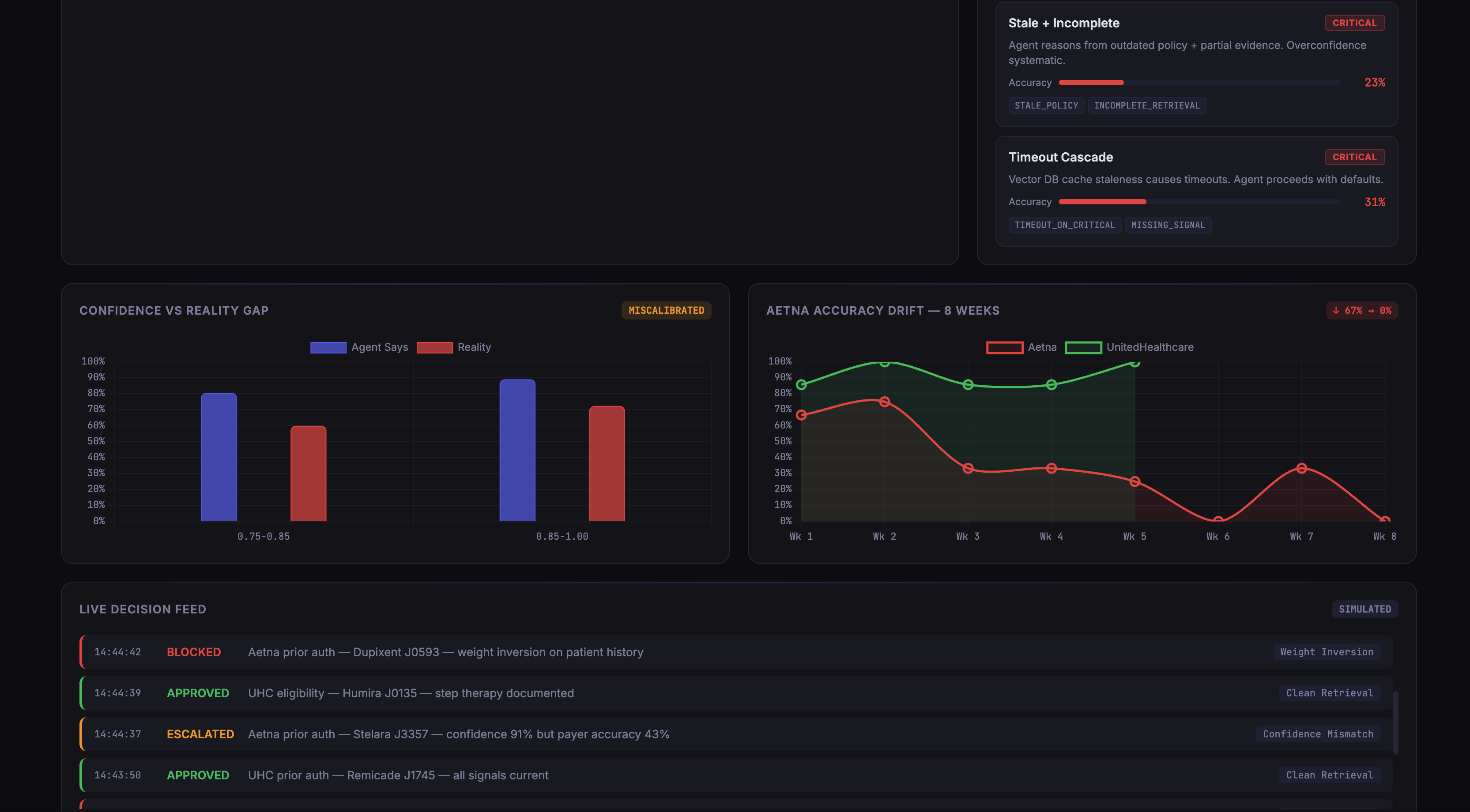
Confidence vs Reality Gap — The agent reports ~89% confidence but actual accuracy is ~72%. The Aetna drift chart shows the 8-week decline from 67% to 0%.
Stage 4 — Authority Gate
The gate combines fidelity, pattern, and reliability data into a verdict:
- FULL_AUTONOMY — Reliability >85%, fidelity >80%, no drift. Agent proceeds freely.
- ACT_AND_NOTIFY — Reliability 65–85%. Proceed but flag for human verification within 2 hours.
- HUMAN_REQUIRED — Reliability <65% or ≥2 critical fidelity failures. Decision blocked.
- QUARANTINE — Drift detected. All decisions for that payer require human review until drift resolves.
Integrations
Datadog — Audit Trail & Drift Monitors
Every verdict is emitted to Datadog as a custom event with full context: decision ID, authority level, fidelity score, pattern detected, reliability score. SENTINEL also creates Datadog monitors that alert when per-payer accuracy crosses threshold — the drift detection feedback loop.
Braintrust — Evaluation Scoring
Each decision is logged to Braintrust as an eval span. When outcomes resolve (days later), the ground truth is attached. This gives a persistent eval dataset: how often SENTINEL's verdicts were correct, which patterns were misclassified, and calibration quality over time.
Cleric — Incident Escalation
When the authority gate issues HUMAN_REQUIRED or QUARANTINE, SENTINEL automatically creates a Cleric incident with the full decision context: the original agent reasoning, the fidelity audit, the pattern match, the reliability profile. A human billing specialist gets a structured investigation package, not a raw alert.
ElevenLabs — Voice Morning Brief
SENTINEL generates a daily reliability briefing script (overnight accuracy, drift alerts, blocked decisions, top patterns) and sends it to ElevenLabs for text-to-speech synthesis. The ops team gets a spoken summary at standup — a different modality for a different workflow.
The Demo: Catching Pattern Delta in Real Time
The hackathon demo runs a pre-seeded scenario with 60 days of synthetic outcomes showing Aetna's drift from 84% to 44% accuracy. Then, live:
- MedAgent submits a Humira prior auth denial for Aetna. Confidence: 89%.
- SENTINEL intercepts via the
sentinel_evaluateMCP tool (through agentgateway with CEL RBAC). - Fidelity audit fires: payer policy is 14 months stale (CRITICAL). Step therapy docs only 40% retrieved (CRITICAL).
- Pattern Delta classified. Historical accuracy: 23%.
- Reliability scorer: Aetna at 44% — drift detected.
- Authority gate: QUARANTINE. Decision blocked.
- Cleric incident created automatically with full reasoning context.
- Datadog receives the verdict event. Braintrust logs the eval.
The jaw-drop moment: the agent was 89% confident in a decision that belongs to a pattern with 23% historical accuracy. SENTINEL caught the gap. Without it, the decision auto-executes.
Live Decision Feed — SENTINEL intercepts decisions in real time. Aetna claims are blocked due to Pattern Delta, while UnitedHealthcare claims pass through cleanly.
agentgateway Playground — Any MCP client can connect to SENTINEL through agentgateway. Tool-level RBAC controls access, and every invocation is logged.
Running It Yourself
# 1. Clone and configure
git clone https://github.com/espirado/agent-secure.git
cd agent-secure
cp .env.example .env # Fill in API keys
# 2. Start SENTINEL with demo data
SEED_DEMO_DATA=true go run ./cmd/sentinel
# 3. (Recommended) Run behind agentgateway
curl -sL https://agentgateway.dev/install | bash
agentgateway -f agentgateway.yaml
# 4. Open agentgateway playground
open http://localhost:15000/ui/playground/
# Connect to http://localhost:3000 and try SENTINEL's MCP tools
# 5. Run the full demo script
chmod +x run_demo.sh
./run_demo.sh
Why This Matters
As AI agents take on more autonomy in high-stakes domains — healthcare, finance, infrastructure — there's a growing need for governance that goes beyond compliance checklists. You need to understand whether the reasoning behind a decision was sound: was the evidence complete? Was it current? Did the agent's confidence actually match reality?
SENTINEL answers those questions at the MCP protocol layer. By running behind agentgateway, every tool invocation is secured with CEL-based RBAC, every call is audit-logged, and the reasoning audit itself is just another MCP tool that any client can call.
The combination of agentgateway's governance primitives with SENTINEL's domain-specific reasoning audits shows what MCP-native agent governance can look like in practice — not bolted on after the fact, but built into the protocol layer where agent decisions actually flow.